깃(git)에 관한 기본 지식
개발자라면 여러 종류의 버전관리 시스템(Version Constol System, VCS)을 사용해 보신 분도 있겠죠. 서로 비슷한 면들이 있겠지만 그래도 깃이 어떻게 동작하는 지 한번 짚어 본다고 해가 될 것은 없겠죠. 시간을 내서 깃 이해하기와 깃 기본을 읽어 보시면 좋겠습니다. 깃 이해하기는 프리젠테이션용 자료로 영문만 있지만 깃 기본은 Pro Git이라는 책의 무료 버전으로 한글로 된 번역도 보실 수 있어요.
깃에 대해서 기본적으로 알아야할 몇가지를 살펴 보겠습니다.
깃은 스냅샷으로 관리됩니다.
기존 버전관리 시스템(서브버전, 퍼포스 등)과 깃과의 큰 차이는 버전 데이터를 관리하는 방식입니다. 다른 시스템은 주로 파일을 중심으로 파일이 변경된 내역을 관리하고 있죠. 데이터를 보는 관점이 어떤 파일이 존재하고 각 파일이 시간에따라 변경된 차이점에 있게 됩니다. 이를 델타 베이스드 버전 관리(delta-based version control)이라고 하죠.
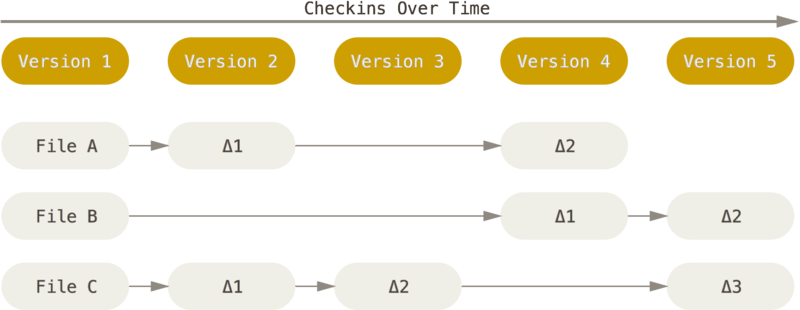
프로젝트 처음에 File A, File B, File C로 Vesrion 1을 시작했습니다. 그리고 File A와 File C에 기능을 구현해서 Version 2가 되었습니다. 이때 File A와 File C는 Version 1 대비 변경된 내용이 delta 1으로 저장이 됩니다. Version 2의 코드를 받아 보려고 하면 원본인 File A와 File C에 변경 사항인 가각의 delta 1을 적용해서 받아오는 거죠.
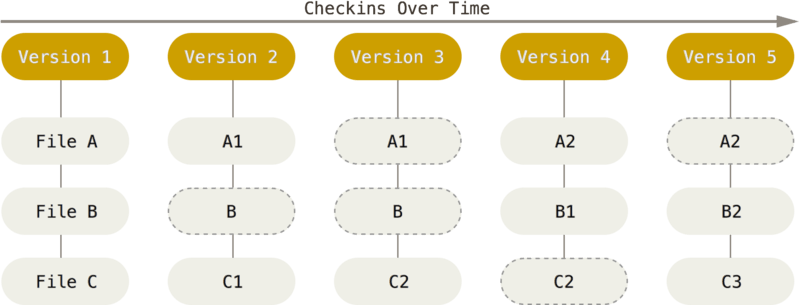
이와는 달리 깃은 아주 다르게 데이터가 관리됩니다. 데이터를 바라보는 관점이 완전히 다른데요. 파일을 하나씩 별도로 보면서 차이점만 따로 관리하지 않고 프로젝트 전체를 스냅샷 형태로 관리합니다. 마치 매 순간마다 프로젝트 전체를 사진으로 찍어서 관리하는 것과 같은데요. Version 1에서 Version 2로 변경이 되면 깃은 Version 2의 스냅샷을 하나 만들어 놓고 그 스냅샷을 가르키는 레퍼런스를 저장합니다. 효율을 위해서 변경되지 않은 File B는 다시 새로 저장을 하는 것이 아니라 이미 저장되어 있는 파일에 링크만 걸어 줍니다. 버전이 변경되는 과정을 보면 마치 연속된 스냅 사진을 보는 것 같습니다.
깃은 대부분의 작업을 로컬에서 합니다.
깃으로 버전 관리를 할때 서버에 연결이 안되거나 인터넷이 없더라도 문제가 되지 않습니다. 이유는 깃이 분산 버전관리 시스템이기때문인데요. 이 말은 데이터가 중앙 서버에만 있는 것이 아니라 분산되어 있는 모든 컴퓨터에 다 있다는 것입니다. 현재 작업을 하고 있는 깃 폴더에 있는 .git이라는 폴더가 바로 모든 데이터를 가지고 있는 곳입니다. 여기서 모든이라는 말은 실제로 모든 히스토리와 데이터를 다 가지고 있다는 뜻입니다. 쉽게 말해서 origin/master와 내 로컬의 master가 동일한 히스토리와 정보를 모두 가지고 있다는 거죠. 물론 여러 개발자가 같이 작업을 할 때 origin/master에는 다른 개발자가 작업한 최신 내용이 더 있을 수는 있습니다. 하지만 git pull 혹은 git fetch를 하면 다시 같은 데이터를 갖게 되죠.
로컬에서 대부분의 작업을 할 수 있게 됨으로 갖는 장점으로는 속도를 꼽을 수 있습니다. 중앙 서버를 갖고 있는 버전 관리 시스템은 예전 작업한 내용을 가져오거나 변경 사항을 저장하기 위해서 네트웍을 통신을 해야만 합니다. 인터넷이 느리거나 서버에 부하가 걸리는 상황이라면 서버 응답을 가다리느라 마냥 멍하니 있어야하는 경우가 생기죠. 하지만 깃에서는 그럴 일이 없습니다. 한달 전 코드를 보고 싶거나, 지금 작업하던 내용을 저장하고 다른 브랜치를 보고 싶더라도 전혀 네트웍을 통해서 다른 서버에 접속할 필요가 업습니다. 모든 정보를 내 로컬에 가지고 있으니까요.
보통 깃은 데이터 베이스에 정보를 추가만 합니다.
깃에서 어떤 작업을 하던 거의 모든 작업은 깃 데이터 베이스에 내용을 추가하는 작업입니다. 이게 왜 중요하냐면요. 깃으로 작업을 하고 있다면 이전 작업 내용을 되돌리는 것이 항상 가능하다는 것입니다. 데이터가 사라져서 찾을 수 없는 경우는 거의 없습니다. 하지만 이말은 우선 작업한 내용을 데이터 베이스에 기록을 한 후라는 가정이 있습니다. 깃에서 사용하는 단어로는 커밋을 한 후를 말합니다.
이 내용을 이해한 개발자라면 한가지 자유를 얻게 됩니다. 소스 코드에 대해서 아무런 시험이나 가능하다는 거죠. 일단 코드를 커밋을 한 후라면 다시 돌아올 수 있는 길이 항상 존재하기때문에 무엇이든 하고 싶은 일을 해도 괜찮습니다.
깃은 브랜치 생성과 머지가 자유롭습니다.
깃은 디자인 단계부터 브랜치를 생성하고 머지하는데 오버헤드가 아주 적도록 만들어 졌습니다. 브랜치는 단순히 스냅샷을 가르키는 레퍼런스 이기때문인데요. 아주 많은 브랜치를 생성하는 것이 가능하고 때로는 권장을 하기도 합니다. 무엇이든 새로운 로지컬한 단위가 있다면 브랜치를 생생해서 관리하는 게 좋습니다. 또 지금 작업하고 있는 것과 분리된 어떤 실험을 하고 싶은 경우에도 고민 없이 브랜치를 생성해도 됩니다. 작업이 끝나서 다른 브랜치에 머지를 했거나, 실험이 끝났다면 필요 없어진 브랜치는 지우면 됩니다.
깃은 모든 데이터를 오브젝트로 저장합니다.
오브젝트에는 네가지 타입이 있는데요. 브롭(blob), 트리(tree), 커밋(commit), 태그입니다. 블롭은 파일을 트리는 디렉토리를 대표합니다. 각 오브젝트는 중복되지 않는 해시로 이름 붙여지는데요. 해시는 각 오브젝트의 내용을 SHA-1 알고리즘으로 생성합니다. 로그를 보거나 깃에서 보여주는 메시지를 보면 이 해시의 앞부분 일부를 보여주는 경우가 많습니다. 또한 깃 명령어를 사용할 때 해시의 일부로 해당 오브젝트를 지정하는데 사용할 수도 있고요. 태그는 다른 오브젝트에 별도의 이름을 하나 더 붙여주는 것과 같습니다. 커밋 오브젝트가 제일 많은 정보를 가지고 있는데요. 트리 아이디, 부모 커밋 아이디, 커밋한 사람의 정보, 로그 메시지 등을 담고 있습니다. 깃 리포짓토리는 이러한 오브젝트를 가르키는 포인터들의 모임과 같은데요. 특별히 이 오브젝트를 가르키는 포인터를 refs라고 부릅니다. .git/refs 폴더에 그 내용이 있습니다.
리포지토리를 클론하면 워킹 카피를 만듭니다.
깃 서버에서 클론(cone)을 한 폴더에 들어가 보면 .git 폴더가 생성되어 있습니다. 이 폴더에는 로컬의 자체 깃 리포지토리 내용을 담고 있죠. 앞서 이야기한 분산 데이터 베이스입니다. .git 폴더에는 다음 커밋에 포함될 스테이징 영역(staging area)을 추적하고 관리합니다. 이 .git 폴더 밖에 있는 모든 파일은 워킹 트리(working tree)라고 부릅니다.
깃에서 관리하는 파일은 세가지 상태가 있습니다.
모디파이드(modified), 스테이지드(staged), 커밋티드(committed)입니다. 커밋티드는 변경된 내역이 안전하게 로컬 깃 데이터베이스에 저장이 되었다는 뜻입니다. 로컬 데이터베이스는 .git 폴더를 말하죠. 스테이지드는 변경된 파일이 다음 커밋에 포함될 내역으로 표시가 되었다는 것입니다. 모디파이드는 변경은 되었지만 아직 다음 커밋될 내용에 포함은 안 된 상태입니다. 이 상태가 가장 주의해야할 상태인데요. 자칫 실수라도 하면 지금 껏 작업한 내용이 연기처럼 사라질 수도 있는 상태입니다.
깃의 일반적인 작업 방식은 수정, 추가, 커밋입니다.
워킹 트리(working tree)에 있는 파일을 수정하는 것으로 작업이 시작됩니다. 수정된 내역은 git add 명령으로 스태이징 영역에 추가를 합니다. 그리고 git commit 명령어로 스테이징 영역에 있는 파일을 커밋하게 됩니다.
깃 실전 가이드
참고자료
- How Git is different
- Git Basics
- 이미지는 Git Basics에 있는 이미지를 가져 왔습니다.